Author: Matillion
Date Posted: Dec 13, 2023
Last Modified: Jun 10, 2025
Data Transposing / Pivoting
Transpose or pivot data between wide and narrow representations.
Three Data Productivity Cloud pipelines that demonstrate techniques for transposing (pivoting) data between wide and narrow representations.
Open example transpose extract and load first.
Example setup
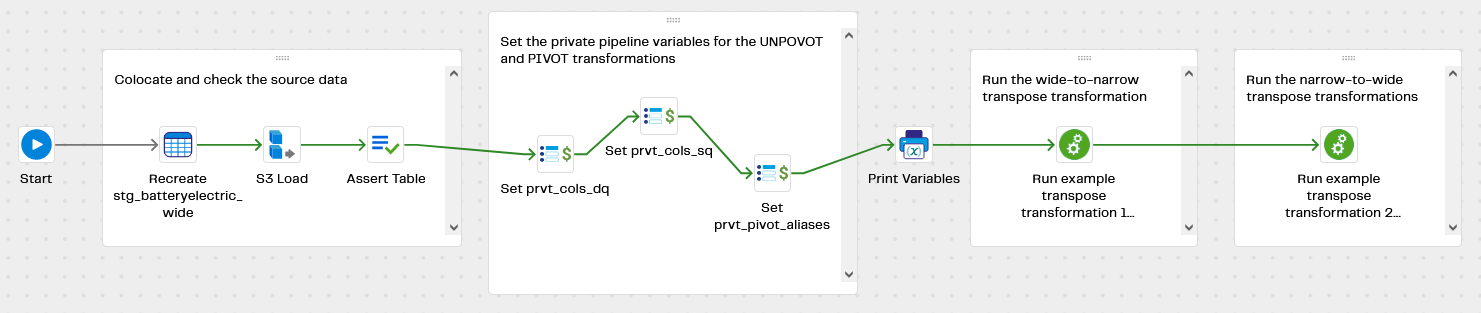
When you run this pipeline, it will copy (colocate) the sample data from our recent assessment of the UK’s Electric Vehicle infrastructure into a new table named stg_batteryelectric_wide. This is a wide table:
- Relatively few rows
- A small number of identity columns (Make and Model)
- A large number of similarly-named columns. In this example they contain values at different points in time
| Make | Model | 2022 Q3 | 2022 Q2 | 2022 Q1 | 2021 Q4 | … | 2010 Q2 | 2010 Q1 |
|---|---|---|---|---|---|---|---|---|
| AIXAM | AIXAM MEGA | 5 | 5 | 5 | 5 | … | 155 | 154 |
| ASTON MARTIN | ASTON MARTIN MODEL MISSING | [low] | [low] | [c] | [low] | … | [low] | [low] |
| etc | … | … | … | … | … | … | … | … |
The data contains some values that are not numeric, either because they were estimated, or were confidential. Also there are values such as 18,974 which are formatted strings rather than real numbers. These will be problematic when it comes to summing the values later. In other words the data is accurate and of high quality, but it needs to be made more consumable so it can be manipulated and interpreted more easily.
There are more than 50 of these “value” columns. So to avoid a lot of hand coding, and therefore to improve productivity, the pipeline automatically sets several variables for the UNPOVOT and PIVOT transformations that will follow.
Data Transposing Wide to Narrow
The first of the two transformation pipelines transposes the data into its narrow format, and creates a new table named stg_batteryelectric_narrow:
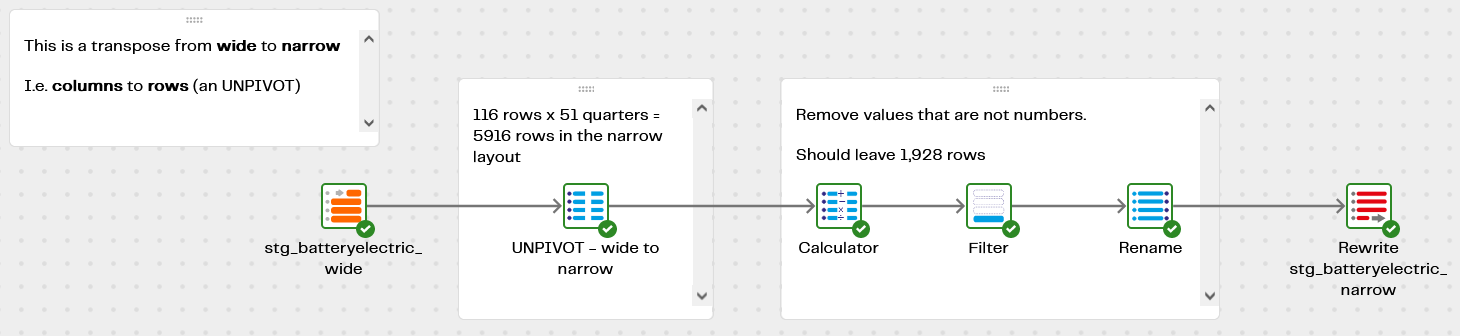
In its narrow format the table retains the two identity columns, but all the values are transposed into date / count pairs like this:
| Make | Model | Quarter | Vehicles |
|---|---|---|---|
| AIXAM | AIXAM MEGA | 2022 Q3 | 5 |
| AIXAM | AIXAM MEGA | 2022 Q2 | 5 |
| AIXAM | AIXAM MEGA | 2022 Q1 | 5 |
| AIXAM | AIXAM MEGA | 2021 Q4 | 5 |
| AIXAM | AIXAM MEGA | 2021 Q2 | 6 |
| … | … | … | … |
| VOLKSWAGEN | VOLKSWAGEN UP | 2014 Q3 | 90 |
| VOLKSWAGEN | VOLKSWAGEN UP | 2014 Q2 | 60 |
| VOLKSWAGEN | VOLKSWAGEN UP | 2014 Q1 | 54 |
| VOLKSWAGEN | VOLKSWAGEN UP | 2013 Q4 | 30 |
It’s exactly the same data, but expressed using more rows and less columns. An important DataOps consideration is that this narrow format offers some protection against schema drift. Adding a new quarter will not require a modification to this table’s structure.
The calculator, filter and rename components remove values such as [low] and [c] that are not numbers. They will be replaced with NULL, which will act as a zero when summed. Strings that look like numbers are replaced by actual numbers.
Data Transposing Narrow to Wide
The second of the two transformation pipelines starts with the narrow format data and pivots it back into wide format at two different granularities:
- stg_batteryelectric_make_model (re-pivoted by make and model)
- stg_batteryelectric_make (re-pivoted and summed by make only)
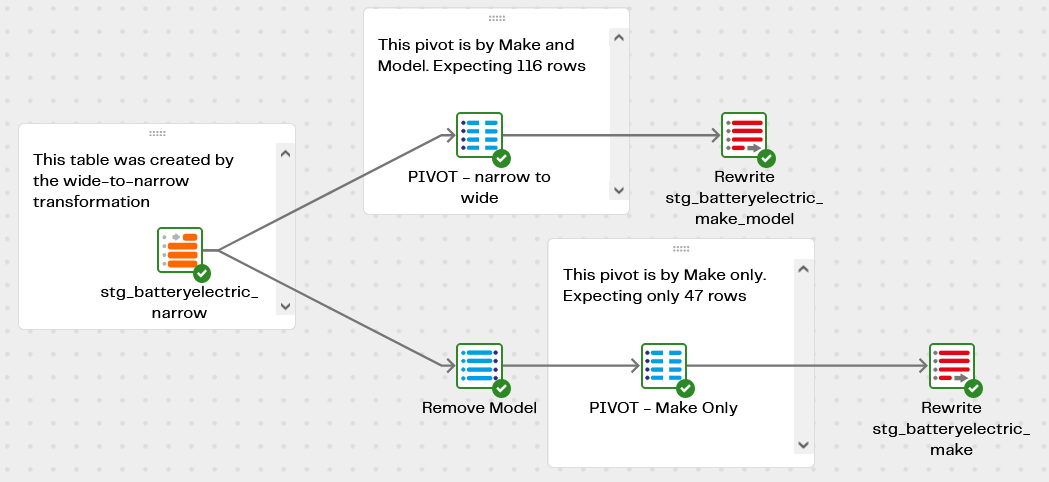
The new stg_batteryelectric_make_model table is almost identical to the original data. The only differences are that the non-numeric values (like [low] and [c]) are gone, and all the value columns are numbers rather than strings.
| Make | Model | COUNT_2021_Q3 | COUNT_2021_Q2 | … |
|---|---|---|---|---|
| AUDI | AUDI E-TRON | 12595 | 10422 | … |
| AUDI | AUDI Q4 | 1414 | 252 | … |
| BMW | BMW I3 | 13895 | 13054 | … |
| BMW | BMW I4 | … | ||
| BMW | BMW IX | 19 | … | |
| BMW | BMW IX3 | 862 | … | |
| BMW | BMW MODEL MISSING | 9 | 8 | … |
In the two PIVOT components you’ll notice the expression for the new cells is SUM("Vehicles"). That means it’s possible to aggregate, or sum, the values at a lower granularity. Removing the Model column results in the new stg_batteryelectric_make table:
| Make | COUNT_2021_Q3 | COUNT_2021_Q2 | … |
|---|---|---|---|
| AUDI | 14009 | 10674 | … |
| BMW | 14785 | 13062 | … |
Transposing data using Matillion Maia
Use the following prompt:
You have a table named stg_batteryelectric_wide.
It is in a "wide" format, with a two part unique key (Make and Model) plus many columns.
Unpivot all columns except Make and Model into rows.
The output table must have four columns: Make, Model, Quarter and Vehicles.
The Vehicles column must be numeric.
Matillion Maia Demonstration
Downloads
Licensed under: Matillion Free Subscription License
- Download transpose-pivot_Databricks_AWS.zip
- Platform: AWS
- Target: Databricks
- Download transpose-pivot_Snowflake_AWS.zip
- Platform: AWS
- Target: Snowflake