Author: Matillion
Date Posted: Oct 31, 2024
Last Modified: May 19, 2025
Surrogate Key Generation
Generate surrogate keys with this set of Data Productivity Cloud pipelines that demonstrates many different methods.
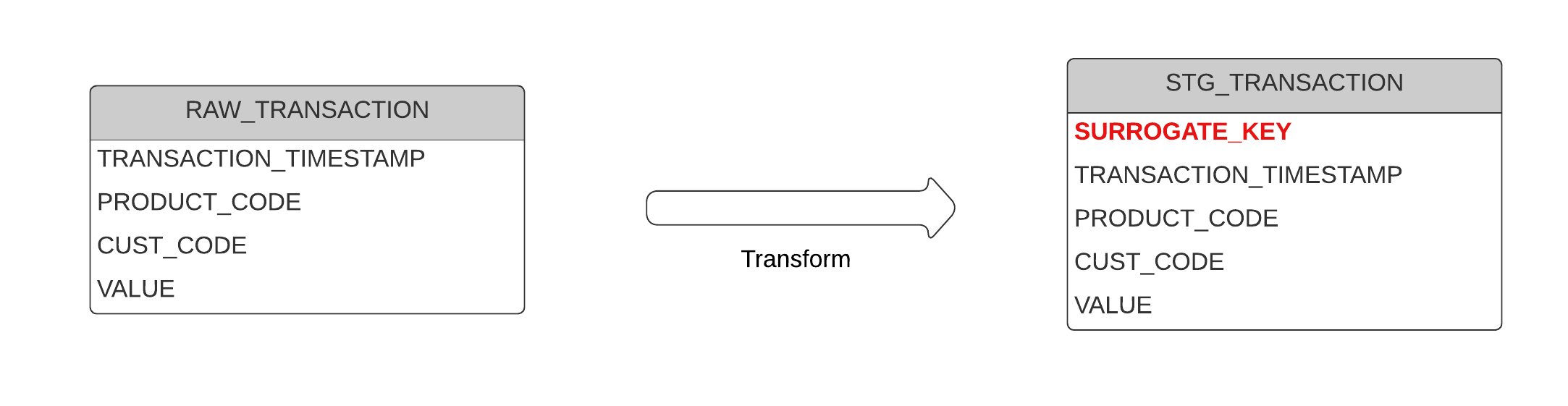
The source data is 100 rows of dynamically generated transaction data, stored in a table named RAW_TRANSACTION. There is no single primary key column or distinctive identifier, but records can be uniquely identified by a combination of:
- TRANSACTION_TIMESTAMP
- PRODUCT_CODE
- CUST_CODE
The pipelines demonstrate different ways to add a surrogate key column when copying data into the target table STG_TRANSACTION.
Using a SEQUENCE object
If your target database supports SEQUENCE objects, start with 2 Sequence Example which creates a SEQUENCE object named SQ_TRANSACTION and runs the transformation afterwards.

The transformation to get the value for the SURROGATE_KEY column is a simple SQL fragment:
SQ_TRANSACTION.NEXTVAL
The sequence is referenced in the Calculator component of 2 Sequence Transformation
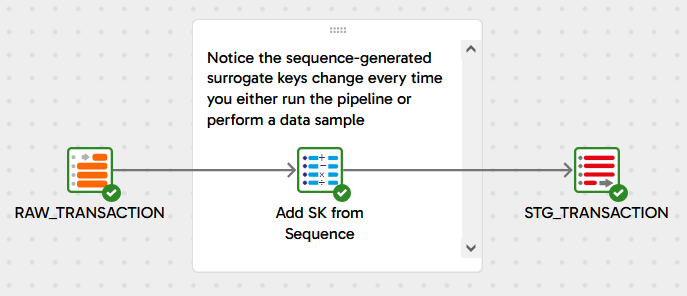
Note that:
- The SEQUENCE guarantees to generate a unique number for every row
- There might be gaps in the generated range (e.g. 1, 2, 3, 1001, 1002, 1003 rather than 1, 2, 3, 4, 5, 6) - especially when input volumes are large
Using an IDENTITY, UNIQUEIDENTIFIER or AUTOINCREMENT
If your target database supports this declarative approach to surrogate key generation, start with 3 Identity Example which declares the SURROGATE_KEY column of the target table to be generated automatically by the database.
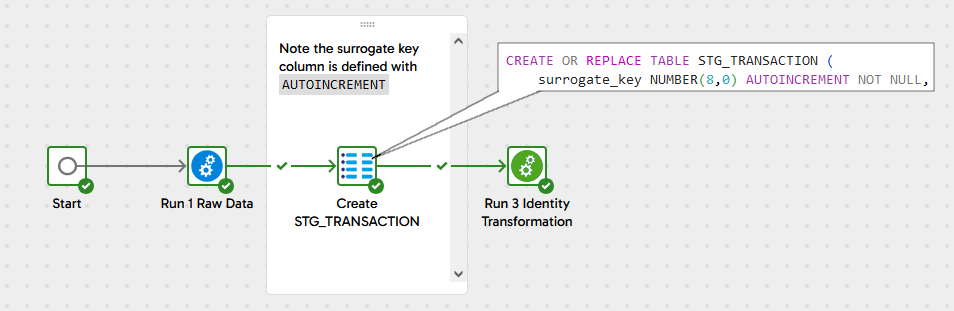
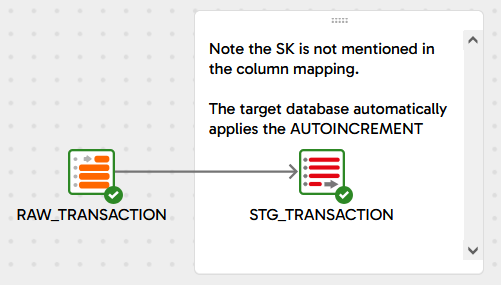
In the transformation to push data into STG_TRANSACTION, simply omit the SURROGATE_KEY column from the UPDATE, INSERT or MERGE statement. When the DML is executed, the database will recognize that no value has been supplied for the surrogate key, and it will generate the unique identifier itself.
Using a GUID
This approach uses a GUID (Globally Unique IDentifier) for the surrogate key in new records.
Start with the 4 GUID Example orchestration pipeline, which just creates the sample data and runs the 4 GUID Transformation pipeline:

The transformation to create the SURROGATE_KEY column is a simple SQL fragment:
UUID_STRING()
The exact syntax will vary according to your target data platform.
High Water Mark + Row Number
Surrogate keys are generated in sequence with this method, starting from a “High Water Mark” where the previous load left off. Start with 5 High Water Mark Example, which just creates the sample data and runs the 5 High Water Mark Transformation pipeline which does all the work.
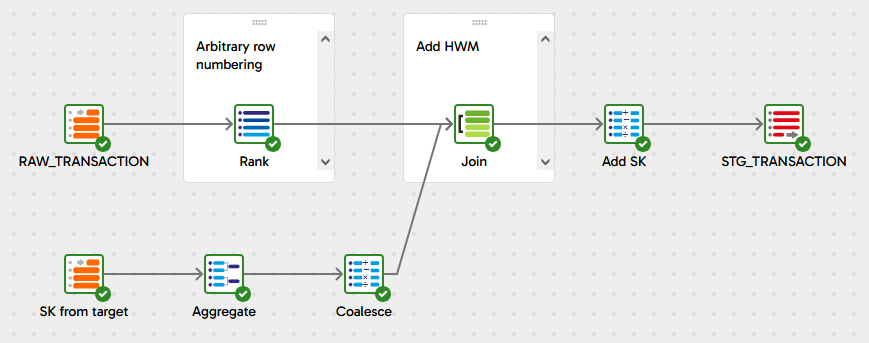
The High Water Mark is calculated by using the highest surrogate key that already exists in the target table, substituting zero if the target table is empty. This is the bottom part of the transformation in the screenshot above.
COALESCE(MAX("SURROGATE_KEY"), 0)
The result is always a single row, which is joined to the source data using a fixed predicate that always evaluates to true. Technically this is a Cartesian join, but one which is guaranteed to not multiply the number of records.
The High Water Mark is added to a ROW_NUMBER() window function over the entire set of input rows. The ROW_NUMBER() produces an ascending sequence, starting at 1 and ordered arbitrarily. The surrogate key is set to the sum of the two numbers.
This method produces very similar results to the SEQUENCE and IDENTITY techniques. Note:
- It is guaranteed to generate a unique number for every row
- There will never be gaps in the sequence, even if an update fails and has to be re-run. The resulting idempotence is useful, at the cost of slightly more compute resources needed at runtime
Clock Based Surrogate Keys
This pattern generally works best with records that are nearly unique already - for example new data from a micro batch increment. New surrogate keys are generated using a millisecond timestamp, plus optionally adding another element to ensure uniqueness. In cases when only one record is ever processed at a time, and processing takes at least a few milliseconds, the timestamp alone is sufficient to create a unique identifier.
The orchestration pipeline 6 Clock Based Example demonstrates this technique inside the 6 Clock Based Transformation pipeline.
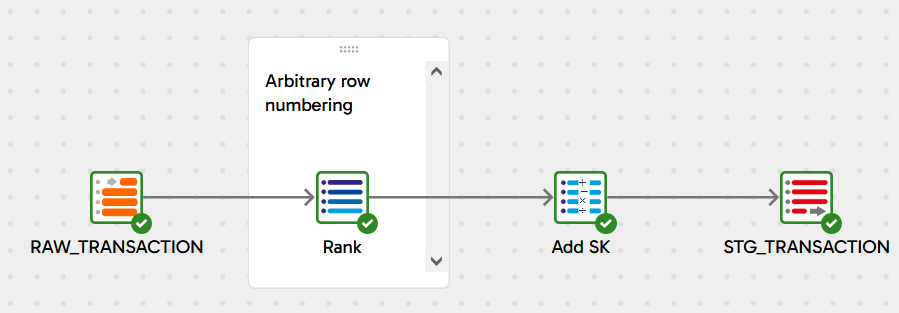
In batch mode SQL like this, all records get processed at exactly the same system timestamp, so a secondary element is required. In this example it’s another ROW_NUMBER() function, so the final SQL fragment is:
TO_CHAR(DATE_PART(epoch_millisecond, CURRENT_TIMESTAMP())) || '_'
|| TO_CHAR(ROW_NUMBER() OVER (ORDER BY "TRANSACTION_TIMESTAMP" ASC))
Concatenated natural key
If the source records contain a combination of fields that is guaranteed to be unique, it’s always possible to generate a single surrogate key field by just concatenating them all together.
The orchestration pipeline 7 Natural Key Example demonstrates this technique inside the 7 Natural Key Transformation pipeline.
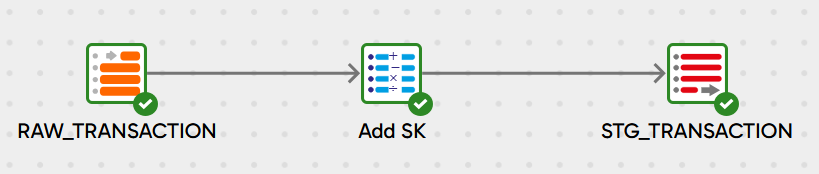
The resulting surrogate key is a (potentially long) string containing all the components of the natural key concatenated together.
Recommendations:
- Use an explicit format mask for dates and floating point numbers. Don’t depend on implicit formatting
- Use a separator character that does not occur naturally in the columns being joined
- Include a version identifier in case the natural key ever changes in future
For example:
'v1-' || TO_CHAR("TRANSACTION_TIMESTAMP", 'YYYYMMDDHH24MISSFF3')
|| '-' || "PRODUCT_CODE"
|| '-' || TO_CHAR("CUST_CODE")
Hash of concatenated natural key
This is a powerful technique used in Data Vault 2.0. It combines several advantages:
- Hash values are relatively small with predictable length, unlike concatenated natural keys which can be much longer
- The method is deterministic: the same source record always generates the same surrogate key
- Hashing is a one-way operation, so PII is stored securely even when - for example - a person’s name is part of the natural key
- Joinability is retained despite the anonymity. A hashed natural key will always join to (and GROUP with) others that have the identical natural key, even though it’s impossible to tell what the original natural key was
The orchestration pipeline 8 Hash Example demonstrates this technique inside the 8 Hash Transformation pipeline. Here is a screenshot that includes a couple of rows of sample data.
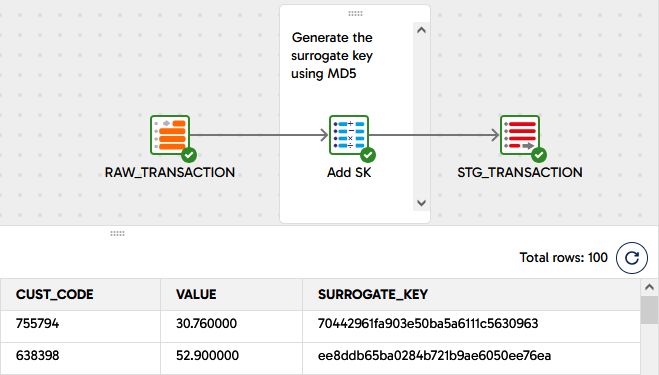
The main thing to be aware of with hash-generated natural keys is that the keys have a fixed size, so the possibility of a “collision” increases as the number of rows increases. A collision occurs when two very different natural keys unexpectedly have the same hash code. This breaks the uniqueness of the surrogate key.
If it becomes mathematically likely that you will encounter collisions, consider combining the Clock Based approach above, prefixing the hash code with a time range that makes collisions unlikely - for example a year, a month, or a date.
Generating a surrogate key using Matillion Maia
Use the following prompt:
Add a surrogate key column named id
Matillion Maia Demonstration
Downloads
Licensed under: Matillion Free Subscription License
- Download Surrogate-Key-Generation_Databricks.zip
- Target: Databricks
- Download Surrogate-Key-Generation_Redshift.zip
- Target: Redshift
- Download Surrogate-Key-Generation_Snowflake.zip
- Target: Snowflake