Author: Ian
Date Posted: Mar 18, 2024
Last Modified: Nov 29, 2024
Reddit Thread Analysis
Extract and analyze comments from a reddit thread using Snowflake and a Large Language Model.
This set of Data Productivity Cloud pipelines starts with text copied from a reddit thread, transforms the data to prepare it for analysis, and finally runs the comments through a Large Language Model (LLM) for categorization.
Snowflake database preparation
To access the original text, open the reddit thread and copy just the comments part. As you can probably guess, I already did that :-) so you can just download the file from here instead. Either way, save the file locally to your device.
Using a SQL client, create a Snowflake stage and copy the file into it:
CREATE OR REPLACE STAGE redditdata;
PUT file://17fr8d5.csv @redditdata;
LIST @redditdata;
Now create a Snowflake file format for a non-delimited “CSV” file, such that every line in the file will be loaded into one column:
CREATE OR REPLACE FILE FORMAT FF_CSV TYPE='csv' FIELD_DELIMITER=NONE;
Use the stage and the file format to copy the data into a new database table. The line ordering is important as you will see, so use the FILE_ROW_NUMBER metadata column to add the row number for each record.
CREATE OR REPLACE TABLE "stg_mh_de_17fr8d5"("row" NUMBER(8, 0) NOT NULL, "text" VARCHAR(32768) NULL);
INSERT INTO "stg_mh_de_17fr8d5" ("row", "text")
SELECT METADATA$FILE_ROW_NUMBER, f.$1
FROM @redditdata (file_format => FF_CSV) f;
.. and tidy up:
DROP STAGE redditdata;
DROP FILE FORMAT FF_CSV;
Extracting comments from semi-structured text
The transformation pipeline Maslow Hierarchy - DE - Begin takes the raw reddit data and converts it into a format ready for analysis.

The transformation steps are as follows. If you install the pipelines you’ll be able to follow along using data sampling.
Regular Expression pattern matching
The first step is to remove the vote scores, because they can make the next step more difficult.
A Calculator component does this, and also replaces any empty strings with a NULL:
CASE WHEN REGEXP_LIKE("text", '[0-9]+') THEN NULL
ELSE TRIM(NULLIF(TRIM("text"), ''))
END
Finite State Machine (Lite)
Looking at the overall structure of lines in the file, two features become apparent:
- Threads are delimited by lines containing just
'level 1' - Comments begin on the 5th line after a
'level n'line, and end two lines before the next'level n'line
The Comments Only component begins to separate the threads by marking just the 'level 1' lines with a simple CASE statement, to create a new column named section. Later, the section identifier will be the line number of its 'level 1' record.
CASE WHEN "text" = 'level 1' THEN "row" ELSE NULL END
Isolating the comments in a semi-structured file like this could be done with a simple finite state machine parse using a language such as awk or lex. However SQL also works well, with the benefit that it’s easy to peek forwards using a LEAD() expression. The following CASE statement isolates the text of interest by removing irrelevant text:
CASE WHEN REGEXP_LIKE("text", 'level [0-9]') THEN NULL
WHEN REGEXP_LIKE(LEAD("text", 1) OVER (ORDER BY "row"), 'level [0-9]') THEN NULL
WHEN REGEXP_LIKE(LAG ("text", 1) OVER (ORDER BY "row"), 'level [0-9]') THEN NULL
WHEN REGEXP_LIKE(LAG ("text", 2) OVER (ORDER BY "row"), 'level [0-9]') THEN NULL
WHEN REGEXP_LIKE(LAG ("text", 3) OVER (ORDER BY "row"), 'level [0-9]') THEN NULL
WHEN REGEXP_LIKE(LAG ("text", 4) OVER (ORDER BY "row"), 'level [0-9]') THEN NULL
ELSE "text"
END
Note that this logic depends on the original line ordering that was captured earlier with the FILE_ROW_NUMBER metadata column.
Thread densification
The second step of separating the threads is to densify the (currently sparse) section column with another windowing function:
LAST_VALUE("section") IGNORE NULLS OVER (ORDER BY "row" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
LAST_VALUE fills the NULL section values by cascading them forwards row by row until the next section starts. This operation also depends on having preserved the original line ordering.
Remove Empty Lines
All the text except the comments has now been removed. Blank lines may influence the LLM so they are removed with a simple Filter component.
Concatenate text for the LLM using LISTAGG
Comments need to be concatenated together by thread to become part of the prompt for the LLM. This is essentially a GROUP BY aggregation, using the LISTAGG function:
SELECT "section",
LISTAGG("text", '\n') WITHIN GROUP(ORDER BY "row") AS "comment"
FROM $T{Remove Empty Lines}
GROUP BY "section"
Now there is just one row per thread, containing all the comments separated by newlines. It’s now in the right format to be sent to an LLM, so it is saved as a new table named mh_de_17fr8d5 using a CTAS operation.
Processing reddit comments with a Large Language Model
The Data Productivity Cloud pipeline Maslow Hierarchy - DE - OpenAI Analyze that runs the review comments through your LLM is simple. The LLM prompt feeds the unstructured text record by record through your LLM. The example in the screenshot below uses OpenAI but you can use alternatives including Azure-managed OpenAI or Amazon Bedrock.
Note that before running this pipeline, OpenAI users must first create a Secret to store your LLM credentials securely. The secret is named OpenAI-Key, which you will find among the OpenAI properties of the component.
Azure OpenAI users must also set the Endpoint and Deployment Name in the component.
Amazon Bedrock users will need to set the AWS region, model category and model name.
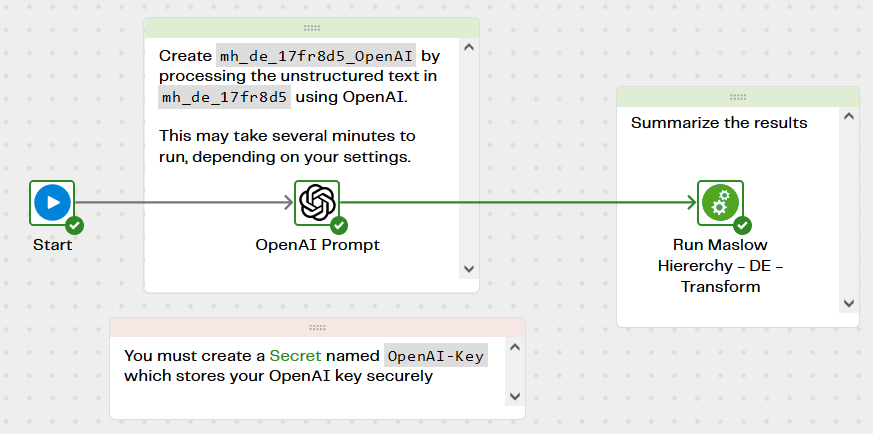
Running the pipeline creates a new table named mh_de_17fr8d5_OpenAI with new columns calculated by the LLM. This is part of a psychology experiment, so the LLM’s task is to assess how the comments reflect users’ feelings about their job.
| New column | Description |
|---|---|
| motivation | A classification of the user’s primary motivation for their work: Prestige (high status, reputation and recognition), Money (being paid well financially) or Satisfaction (the person likes their job) |
| esteem_score | Corresponding to level 4 of Maslow’s hierarchy, this is a score between 0 and 10 on the level of self-worth, accomplishment, and respect indicated by the comments |
| self_esteem | A few words summarizing the user’s level of pride, dignity, independence and assurance in their work |
| prestige | A few words summarizing how much the user’s statement indicates respect from others, reputation, status and prestige |
| actualization_score | Corresponding to level 5 of Maslow’s hierarchy, this is a score between 0 and 10 depending how much the statement indicates self-fulfillment, personal growth, and achievement |
The results from this pipeline will vary from run to run because at normal temperatures the output from an LLM is nondeterministic. This especially applies to the two textual outputs. The esteem and actualization scores should remain broadly consistent, however.
Reading the semi-structured LLM output
After the AI Prompt component has created the new table containing the processed records, it needs to be read using another transformation pipeline: Maslow Hierarchy - DE - Transform:
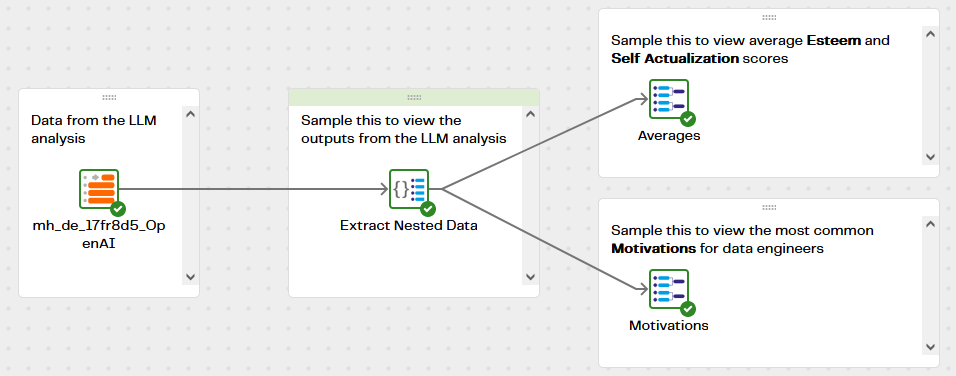
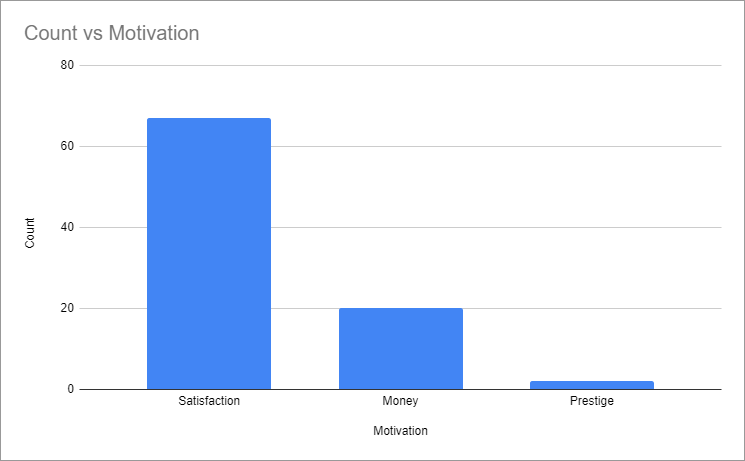
This pipeline extracts the LLM outputs from their JSON representation, and performs some aggregation. Use a data sample on the Averages and Motivations components to see what makes Data Engineers tick. Your mileage may vary, but this is what I found:
Downloads
Licensed under: Matillion Free Subscription License
- Download reddit-thread-analysis_Snowflake.zip
- Target: Snowflake