Author: Matillion
Date Posted: Feb 20, 2024
Last Modified: Nov 29, 2024
Barista demo - using AI to process unstructured data
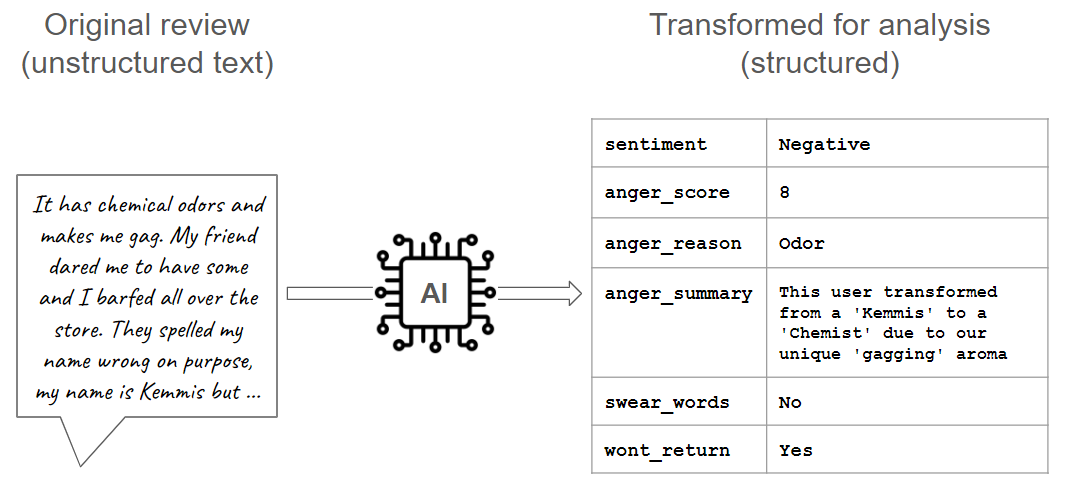
Use a Large Language Model (LLM) to process unstructured data with this set of Data Productivity Cloud pipelines.
The pipelines demonstrate how to use the Data Productivity Cloud AI Prompt components to convert unstructured text into structured data, to make it ready for analysis. The sample data is a set of imaginary barista coffee reviews.
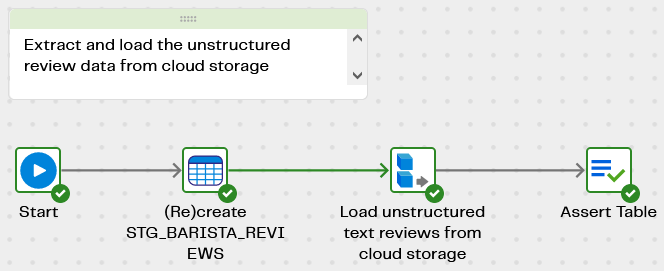
Start by opening the orchestration pipeline to load the sample data.
Load the unstructured text data
The first pipeline in the set is Barista Reviews - Extract and Load which copies the unstructured barista review data into a table named STG_BARISTA_REVIEWS in your cloud data platform.
The original data is held in cloud storage. There are many records, and every one includes the identity of the reviewer alongside their comment, plus various other fields such as the review date and location.
Processing text reviews with a Large Language Model (LLM)
The Data Productivity Cloud pipeline Barista Reviews - OpenAI that runs the review comments through your LLM is simple. The only active component in the pipeline is an LLM prompt, which feeds the unstructured text record by record through your LLM. The example in the screenshot below uses OpenAI but you can use alternatives including Azure-managed OpenAI or Amazon Bedrock.
Note that before running this pipeline, OpenAI users must first create a Secret to store your LLM credentials securely. The secret is named OpenAI-Key, which you will find among the OpenAI properties of the component.
Azure OpenAI users must also set the Endpoint and Deployment Name in the component.
Amazon Bedrock users will need to set the AWS region, model category and model name.

Running the pipeline creates a new table named BARISTA_REVIEWS_PROCESSED_OPENAI with new columns calculated by the LLM:
| New column | Description |
|---|---|
| anger_score | A score between 0 and 10 depending on the level of anger in the review |
| anger_reason | One word describing the reason why the customer is angry |
| sentiment | Sentiment analysis, defined here as Positive, Neutral or Negative |
| anger_summary | A deliberately humorous summary of the customer’s comment |
| swear_words | Set to Yes if there were swear words in the review. Otherwise No |
| product_involved | The product name involved (if any). This is an example of Named Entity Recognition (NER) |
| wont_return | Set to Yes if the customer indicates that they will never come again to the shop. Otherwise No |
The results from this pipeline will vary from run to run because at normal temperatures the output from an LLM is nondeterministic. This especially applies to the anger_summary text. The sentiment analysis scores should remain broadly consistent, however.
Integrating the LLM output
The new columns added by the LLM are based only on the review comment. A final transformation pipeline Barista Reviews - Transform and Integrate is used to integrate them back together with all the original fields, including the review date and location.
Remember to adjust the name of the AI-processed Barista Reviews component depending which LLM provider you used.
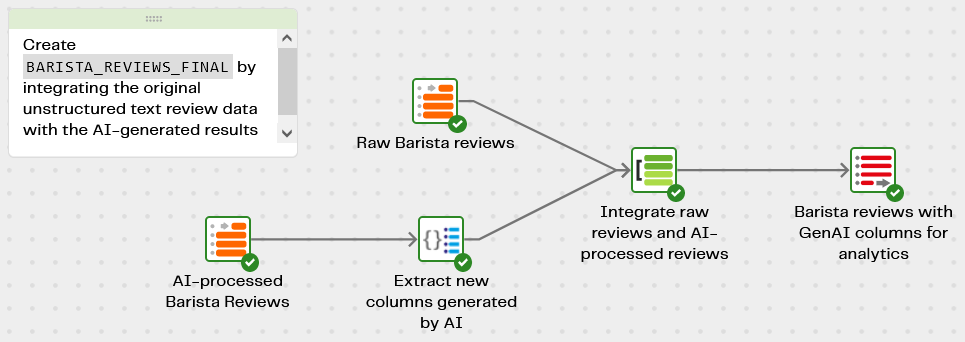
Output from this transformation pipeline is another new database table, named BARISTA_REVIEWS_FINAL. It contains all the original columns from the data source, plus the new columns added by the AI. This table is the one to use for downstream analysis and dashboarding. For example:
- The review date is useful to look for trends over time
- The location can help spot geospatial variation, or differences between stores
Downloads
Licensed under: Matillion Free Subscription License
- Download Barista Demo_Snowflake.zip
- Target: Snowflake