Author: Ian
Date Posted: Feb 2, 2024
Last Modified: Feb 3, 2024
Incremental Load Data Replication Strategy in a Medallion data architecture
This article describes the technicalities of the incremental load data replication strategy in a Medallion data architecture.
Understanding Incremental Load Data Replication
Incremental load data replication is a simple strategy which involves copying changed records from a source to a target system. In this article I will describe the high water mark implementation, sometimes known as “logical” change data capture (CDC) to distinguish it from log-based “physical” CDC.
This strategy is particularly useful in the following cases:
- When you need to quickly replicate data on demand, for example right before a daily metrics update
- When run continuously, to keep a copy of data up to date within a few minutes of real time
This strategy requires that the source table has:
- a primary key
- a way to identify changes. This has to be an always-ascending attribute such as a last-updated timestamp or an integer audit sequence, which the source system updates every time a record is created or modified
Incremental load replication does place load on the source system, as queries are executed against it to fetch the data. The load on the source system is lighter than with a full data replication strategy
Incremental Load Replication Data Architecture
With incremental load data replication, changed data is first extracted from source and loaded into the bronze area of the target database. At this point the data is still in its original, raw, system-specific format. Only the changed records exist in the bronze layer.
After the extract and load, the data is transformed into its generic, system-neutral format in the silver layer. The transformations can be simple if the raw data is already similar to the desired target. Data transformations are likely to include datatype changes and naming standards.
Updates to the silver layer table are made using a MERGE operation, with either inserts or updates depending on the primary key of the source table. To make the pipelines operationally robust it is important to include deduplication logic during this stage of data transformation
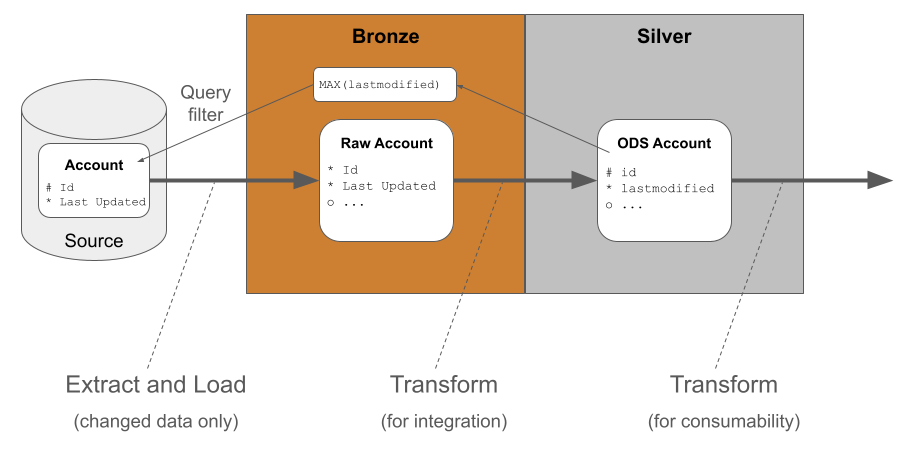
Note the naming alterations in the silver layer table, and the fact that the primary key constraint is ignored in the bronze layer, but retained in the silver layer. Bulk load utilities don’t usually play well with primary keys. For more information on the notation please refer to this article on Data Modeling Techniques.
Storing data in the silver layer does not necessarily make it any easier to read. So a second layer of data transformation - from silver to gold - is often used to render the data in a more consumable way. The output is usually a star schema, or completely denormalized (“flat”) tables - sometimes known as One Big Table or “OBT”’s.
From a DataOps perspective it is helpful to perform this second layer of transformation using database views.
Advantages of using a silver layer ODS table
I’ll take the example of an “Account” table. Using the ODS table as an intermediate has several advantages:
- It is a generic “Account” table rather than being source-system-specific. This enables you to much more easily integrate a second source of account data in future
- Using it to create convenient star schema objects as views means never having to manually refresh the star schema. This big DataOps advantage also means the logic is independent of the extract-and-load method. You could switch to a full data replication strategy at any time without any further refactoring
- Whenever the source schema does change (i.e. schema drift occurs) then you can deal with the changes in one place: the Bronze to Silver data transformations. This is easier than having to refactor multiple star schema objects - another DataOps advantage
In other words, separate stages of data transformation are used for integration and for consumability. Distinguishing between these two aspects is one of the hallmarks of a robust, production-grade data pipeline architecture.
Full vs Incremental loading
Incremental load data replication has the advantage of performance. Every load guarantees that all source changes are synchronized. The approach can be used for very large tables and is most efficient if only a small proportion of the dataset is updated each time.
In contrast, a full load - characterized by reloading the entire dataset every time - is simpler but places greater load on the source system. Transferring a potentially large amount of data means increased resource utilization, and consequently slower processing times.
Hard vs Soft deletes
The difference between hard and soft deletes lies in how records are handled when they are marked for removal. The difference can have an important impact on data replication.
- A hard delete is simple: the record is permanently removed from the database. This results in the immediate and irreversible elimination of the data
- In contrast, in a soft delete, instead of physically erasing a record, it is flagged to indicate that it is no longer active or valid. The metadata is captured in a status field
Hard deletes ensure cleaner and more efficient storage. They may be required for operational reasons, for example data privacy laws. Hard deletes result in a loss of historical context, and can pose challenges if audit trails or historical analysis are needed. A soft delete allows both the retention of historical information and ongoing referential integrity. But consumers of the data are expected to use additional logic to filter out deleted records during queries. One well known example of soft deletes occurs in a slowly changing dimension.
Hard deletes are difficult to detect using a logical incremental load strategy. You can’t extract and load a deleted record from a source database, because it no longer exists. Full load data replication offers a solution to this problem, since the data in the target table is entirely replaced every time.