Classify job titles using zero-shot and few-shot learning with a Large Language Model (LLM) in a Data Productivity Cloud pipeline.
These pipelines extract job titles from Salesforce, and run them through an LLM to
- Standardize them into a defined set of job titles
- Categorize them as ‘IC’ (Individual Contributor) or ‘Manager’
The results are saved into a lookup table for quick reference in future.
Extract Salesforce Job Titles
Start with the Job Titles - Extract Salesforce Titles pipeline, to extract the top 1000 job titles from your Contacts.
The extracted job titles are written to a staging table called stg_salesforce_title in your target Cloud Data Platform. You will need to change the Authentication property to whatever your own Salesforce OAuth is named.
Find Unique Job Titles
Now run Job Titles - Get Unique to narrow down the extract to only the unique job titles that are not null or blank.

OpenAI Prompt
To classify the unique job titles, run the Job Titles - Run LLM pipeline next.
Note that you will need to replace OpenAI-Key with whatever your OpenAI API key secret is named.
It classifies the job titles in tmp_distinct_job_title, created by the previous pipeline, using prompt techniques with a large language model, including zero-shot learning and few-shot learning. Results are saved to a new table named tmp_job_title_openai.
The opening instruction to the LLM is as follows:
You are responsible for interpreting a job title given as input.
Analyze the core essence, responsibilities, and lexicon associated with the job title.
Remember that a job title may have different regional nuances, industry-specific terminologies, and seniority level.
It may be provided in a language other than English.
Zero-shot learning
Zero-shot learning enables models to intelligently handle tasks they haven’t explicitly been trained for. This technique is particularly valuable in environments where data is scarce or constantly evolving. This example is a case in point: the desired list of classifications is tactical in nature and likely to change in future. For data engineers, zero-shot learning enhances the efficiency of deploying machine learning models in varied environments, and opens new avenues for automated decision-making systems lacking relevant training data.
After the above opening instruction, the following zero-shot learning prompt is used to classify job titles into a predefined list
Your task is to standardize the supplied job title into one from this list: "Data analyst", "Data scientist", "Data architect", "Data engineer", "Database administrator", "Database designer", "CIO", "CTO", "IT director", "Development manager", "Data processing manager", "Security manager".
Your aim is to instill standardization and accuracy.
You must respond with the most closely matching job title from your designated list.
If a job title doesn't have a good match, you're authorized to respond with "Other".
Few-shot learning
Few-shot learning is an excellent way to put an LLM to work on a classification problem with a very limited amount of training data. The LLM leverages its prior knowledge from related tasks and applies this to new cases when only a handful of examples are provided. This capability is especially valuable in data-sparse environments where obtaining large datasets is impractical or impossible.
Again, after the above opening instruction, the following few-shot learning prompt is used to classify job titles as Individual Contributors or Managers.
You will be classifying a job title into two categories: 'IC' (Individual Contributor) or 'Manager'.
You'll receive input in the form of a job title, and your task is to analyze this input and determine the likely category.
Keep in mind, though, that the job title may not explicitly include the words 'Manager' or 'IC'.
Instead, it might hint at the nature of the job.
For instance, job titles such as 'Software Developer' or 'Graphic Designer' often represent individual contributors, while 'Project Lead' or 'Operations Supervisor' may well signify managerial roles.
The potential ambiguity calls for your creative and contextual interpretations.
Despite the possible complexity, you're still required to provide only one output: either 'IC' or 'Manager'.
Cache the LLM output
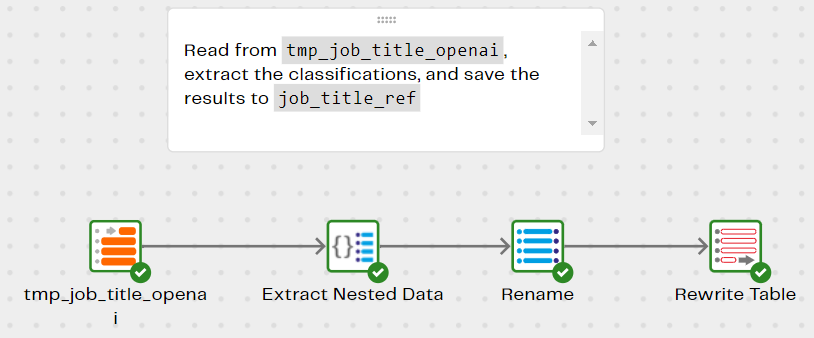
Rather than re-run the LLM categorization for every newly arriving job title, it’s much more efficient to cache the results into a database table, and search that first. Only cache misses need to be run through the categorization in future. The Job Titles - Save Results pipeline saves the results into a table named job_title_ref for this purpose.
Downloads
Licensed under: Matillion Free Subscription License
Download Unstructured-Text-Classification-Job-Titles-SF.zip
- Target : Snowflake
Installation instructions
How to Install a Data Productivity Cloud PipelineAuthor: Matillion