Run sentiment analysis on unstructured conversation transcripts integrated from three different sales systems.
Conversation transcripts are sourced from:
- Salesforce Opportunity table
- Salesloft conversations API, via Amazon Transcribe
- Gong API
This unstructured text will be integrated using Data Productivity Cloud pipelines that create and populate a very simple Data Vault model, with one Hub and three Satellite tables.
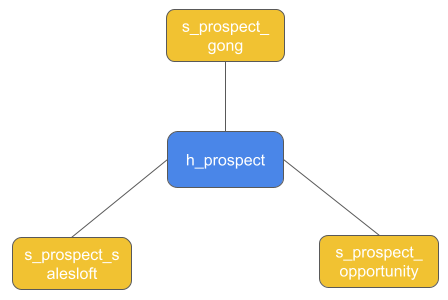
Data Vault setup and load
Begin with the Sales Sentiment - Init pipeline, which sets up the empty Data Vault structures and loads them.
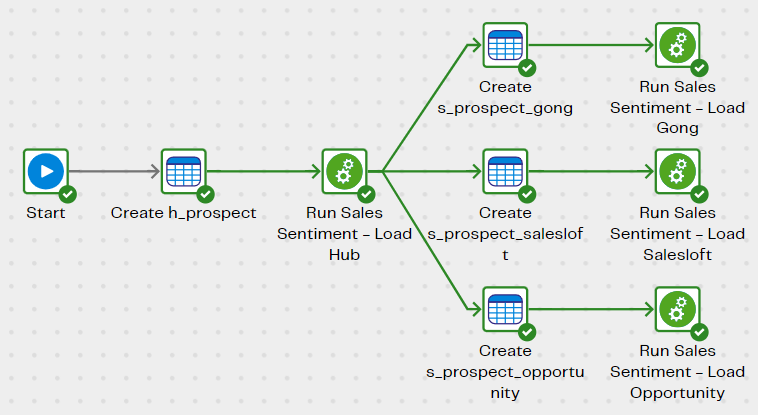
Note that these pipelines read from tables that have already been extracted and loaded into the target cloud data platform.
You can use your own data as input, sourced from your own systems. But if you prefer you can use fabricated test data downloaded from this page.
Using fabricated data
Create these three tables to store the data:
CREATE TRANSIENT TABLE "stg_sales_sentiment_gong" ("prospect_id" INTEGER NOT NULL, "data" VARIANT NOT NULL);
CREATE TRANSIENT TABLE "stg_sales_sentiment_salesloft" ("prospect_id" INTEGER NOT NULL, "data" VARIANT NOT NULL);
CREATE TRANSIENT TABLE "stg_sales_sentiment_opportunity" ("prospect_id" INTEGER NOT NULL, "data" VARCHAR(16384) NOT NULL);
The following files contain the fabricated test data.
- stg_sales_sentiment_gong.csv.gz
- stg_sales_sentiment_opportunity.csv.gz
- stg_sales_sentiment_salesloft.csv.gz
In each case, download the file from this page, copy it into your cloud storage, then transfer it into the appropriate stg_ table using a cloud storage load component.
Data Vault Integration
Accurate sentiment analysis requires that all the conversations are gathered by prospect, and aggregated into one long piece of text. Data Vault is an excellent choice for this kind of data integration task.
The Sales Sentiment - Integrate transformation pipeline joins the Hub table to all three Satellite tables.
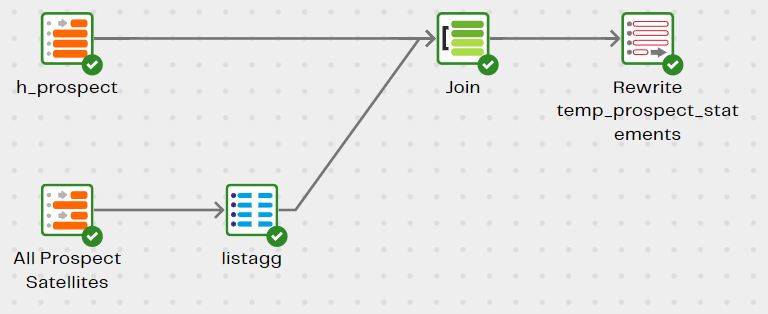
The Hub table defines the granularity: one row per prospect.
A Multi Table Input component can be used since all the Satellite tables have an identical structure.
An SQL LISTAGG operation converts the many short lines of text into one long line per prospect.
The resulting data is saved to a new table named temp_prospect_statements.
Sentiment Analysis data pipeline
This Data Productivity Cloud orchestration pipeline uses an OpenAI Prompt to invoke the gpt-3.5-turbo large language model, passing it a prompt containing context from the temp_prospect_statements table.
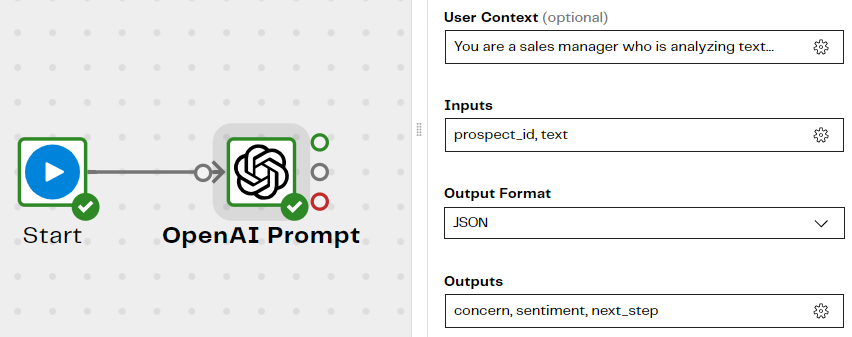
The component takes the prospect_id and text columns as inputs, runs them through the AI model and returns three things:
- concern - the main concern expressed in the text, as a single word
- sentiment - a sentiment score from 1 to 10
- next_step - a short recommendation that will help expedite the sales process
These outputs are written to a new table called temp_prospect_statements_openai.
To run this component yourself, save your own OpenAI API key as a secret and choose its name from the Connect > API Key dropdown list.
Checking the results
The Sales Sentiment - Results transformation pipeline reads the temp_prospect_statements_openai table and examines the results.
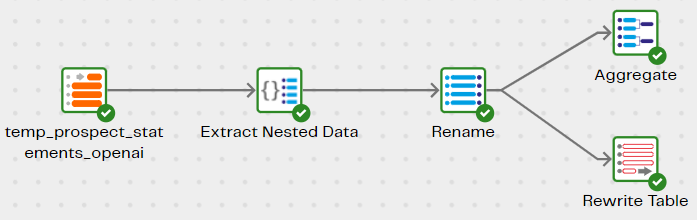
- Multiple outputs were generated, so an Extract Nested Data component relationalizes them into columns
- Use a data preview on the Aggregate component to get a quick summary of the top concern expressed by prospects
- Run the pipeline and use the generated
actionable_insights_sales_sentimenttable to use the AI-generated, prospect-specific insights
Downloads
Licensed under: Matillion Free Subscription License
Download Sales-Sentiment-Snowflake.zip
- Target : Snowflake
Download stg_sales_sentiment_gong.csv.gz
- Purpose : Fabricated conversation data from the Gong API
Download stg_sales_sentiment_opportunity.csv.gz
- Purpose : Fabricated conversation data from the Salesforce Opportunity table
Download stg_sales_sentiment_salesloft.csv.gz
- Purpose : Fabricated conversation data from the Salesloft conversations API, via Amazon Transcribe
Installation instructions
How to Install a Data Productivity Cloud PipelineAuthor: Matillion